Reliable and Scalable Robot Policy Evaluation with Imperfect Simulators
* Equal contribution, † Equal contribution

* Equal contribution, † Equal contribution
Our goal is to evaluate a policy by computing bounds on its mean real-world performance on a diverse environment distribution \(\mathcal{D}_{\text{env}}\). We present a framework that augments real-world evaluations with simulation evaluations to provide stronger inferences on real-world policy performance that could otherwise only be obtained by scaling up real-world evaluations.
Rapid progress in robot manipulation driven by imitation learning, foundation models, and large-scale datasets has enabled generalization to a wide-range of tasks and environments. However, rigorous evaluation of these policies remains a challenge. Typically in practice, robot policies are often evaluated on a small number of hardware trials without any statistical assurances. We present SureSim, a framework to augment large-scale simulation with relatively small-scale real-world testing to provide reliable inferences on the real-world performance of a policy. Our key idea is to formalize the problem of combining real and simulation evaluations as a prediction-powered inference problem, in which a small number of paired real and simulation evaluations are used to rectify bias in large-scale simulation. We then leverage non-asymptotic mean estimation algorithms to provide confidence intervals on policy performance. Using physics-based simulation, we evaluate both diffusion policy and multi-task fine-tuned \(\pi_0\) on a joint distribution of objects and initial conditions, and find that our approach saves over \(20\%\) of hardware evaluation effort to achieve similar bounds on policy performance.
We would like to estimate expected performance of a policy \(\pi\) according to a bounded evaluation metric \(M\) over some distribution of tasks and environments \(\mathcal{D}_{\text{env}}\). While gold-standard, tackling this problem using only real-world evaluations is often expensive and time-consuming. On the other hand, simulation evaluations are relatively easier to scale, but can be biased, leading to inaccurate estimates of real-world performance.
This motivates the central question of our work: Can we make valid inferences on the real-world performance of a policy by combining a small amount of real evaluations with a large number of simulations? To answer this question, we present SureSim: Scalable and Reliable Evaluation with Simulation.
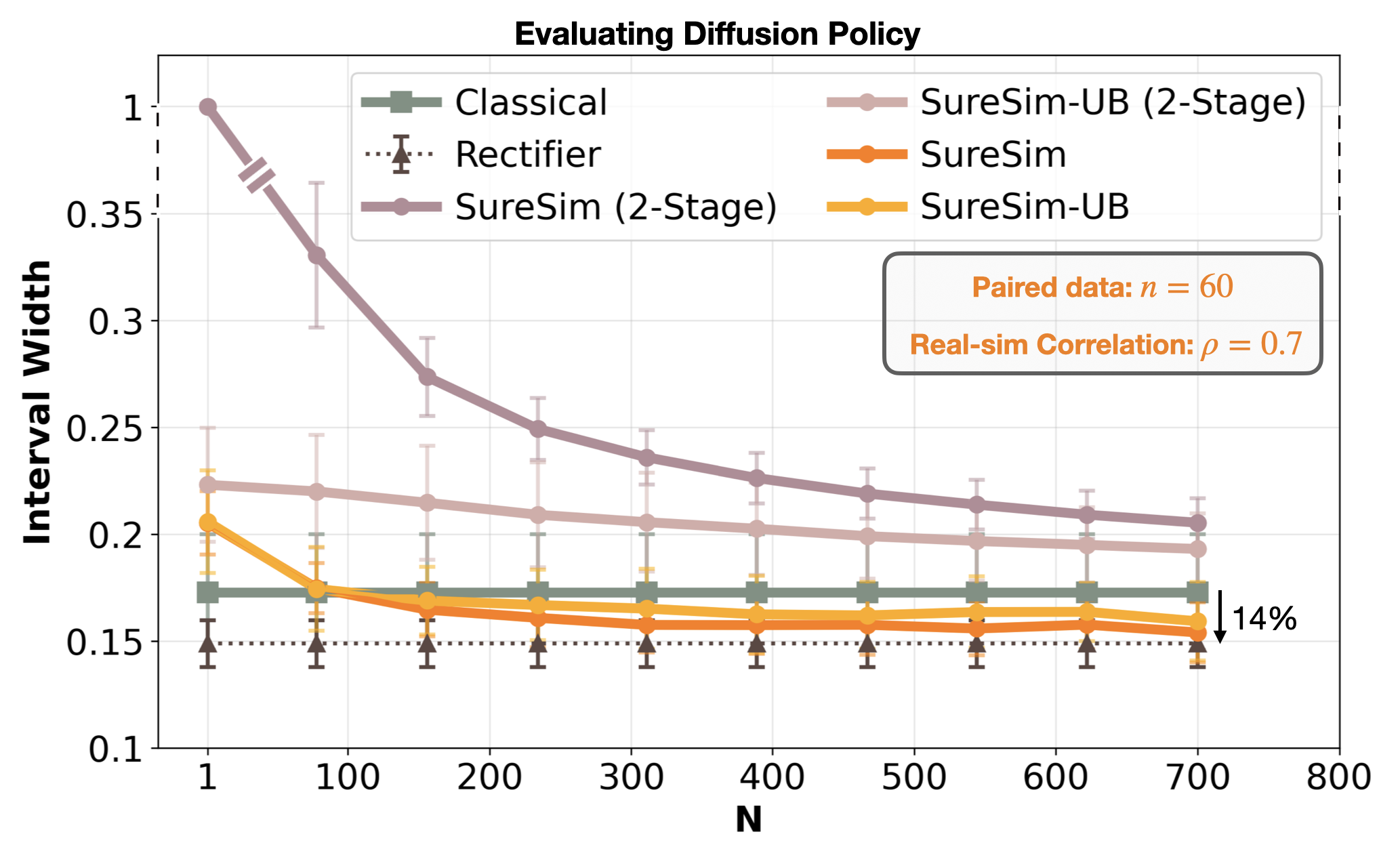
We set up a real2sim pipeline to collect a small number of paired evaluations in both real and simulation environments. This paired dataset allows us to quantify the bias in simulation evaluations and rectify predictions from large-scale simulations. Importantly, the rectifier is related to the correlation between the paired real and simulation evaluations. In a sense, it quantifies the real-simulation gap and provides a lower bound on the advantage (e.g., minimizing confidence interval width, saving hardware evaluations) we can expect from scaling simulation. If the rectifier variance is smaller than the variance in real evaluations, we can expect to save on real-world evaluations.
Relative to the size of the paired dataset, we collect a large number of additional simulations. By running large-scale simulation tests, we can further improve the accuracy of our performance estimates.
Using our framework, we evaluate diffusion policy and a multi-task fine-tuned \(\pi_0\) on a joint distribution of tasks and initial conditions. We choose the pick-and-place family of tasks, parameterized by different object types.
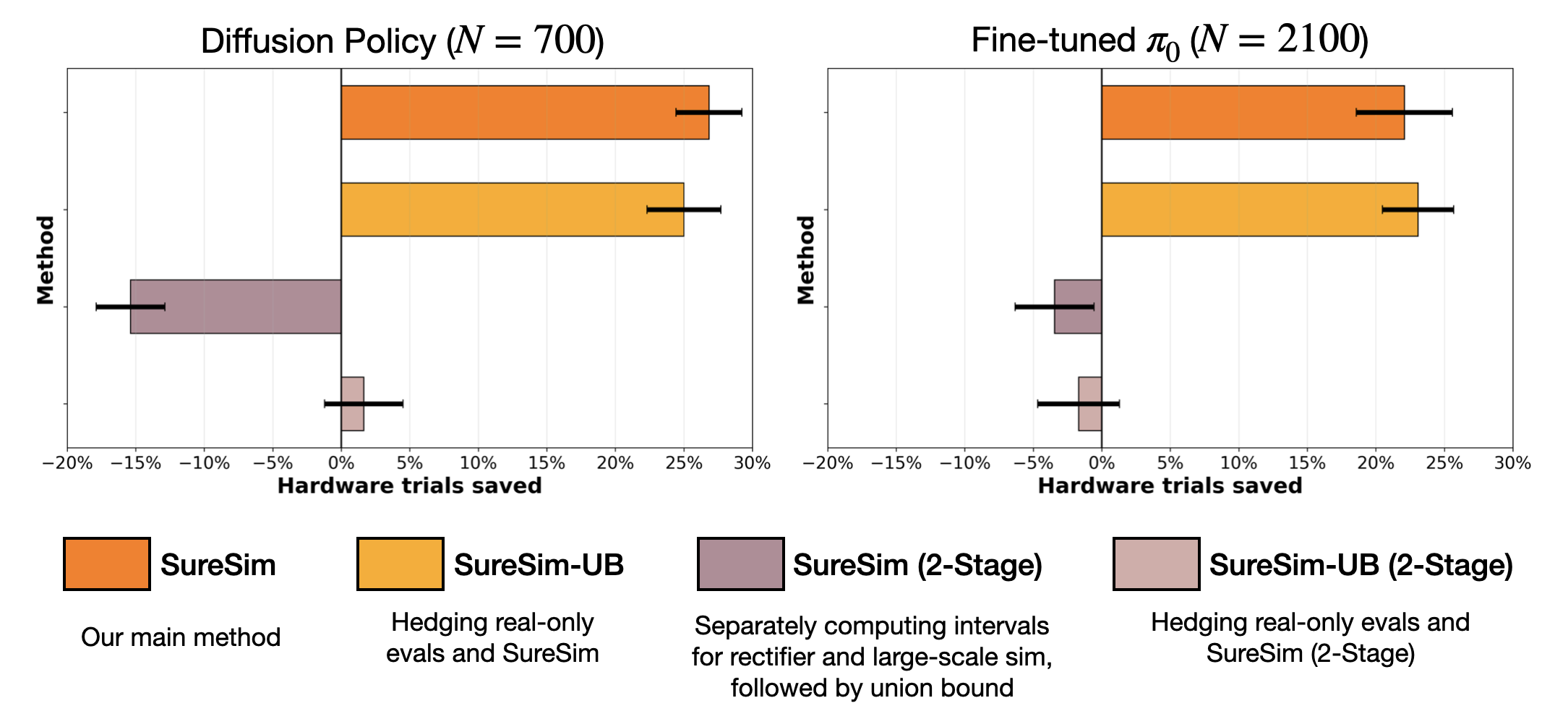
Compared to obtaining confidence intervals with real-world only trials, SureSim leverages simulation effectively, requiring fewer hardware evaluations to achieve similar bounds. SureSim saves 20 - 25% hardware evaluations to get similar bounds on policy performance.
Instead of scaling up hardware evaluations, we can scale up simulation evaluations up to the limit of the real-simulation gap.
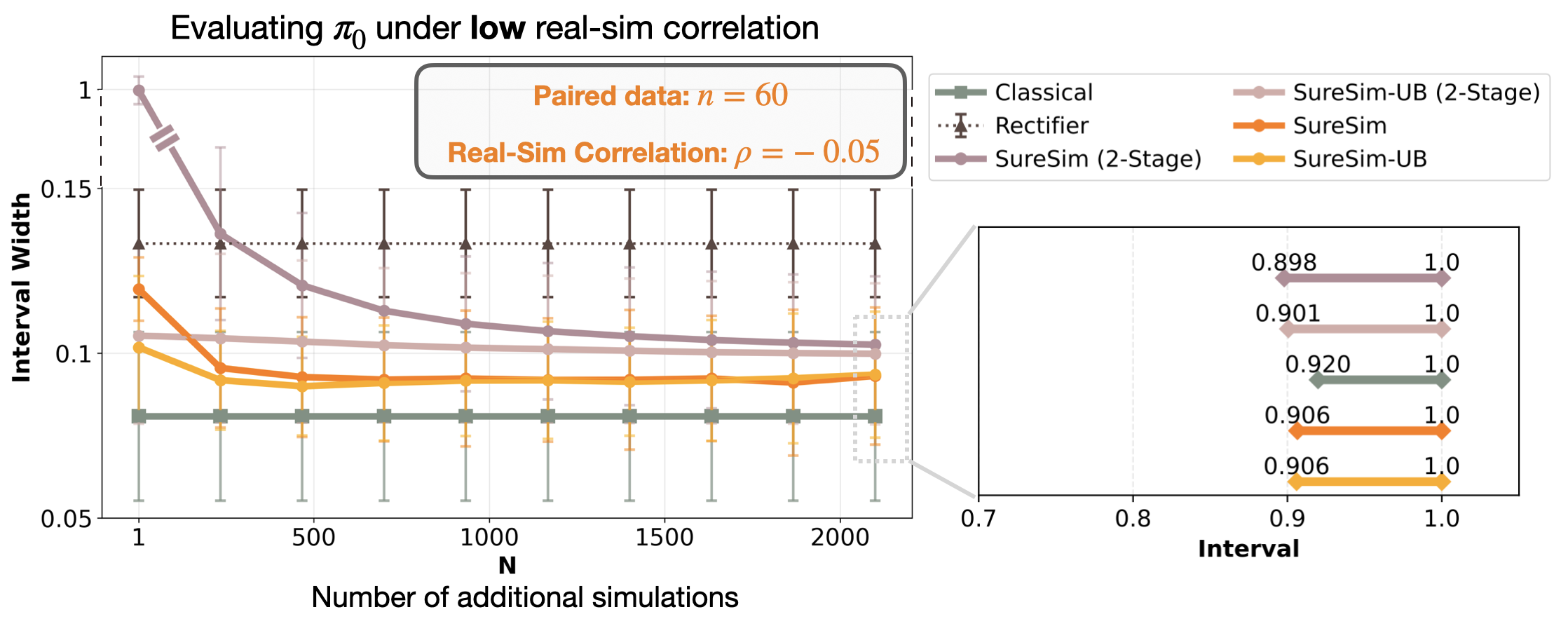
In low correlation settings, real-world-only evaluation gives the tightest bounds on policy performance. SureSim is effective when simulation is more predictive of real-world performance than the variance in real data. Yet, even under high real-simulation mismatch, SureSim returns reliable confidence intervals. Moreover, we can check for the level of mismatch before investing computational effort in scaling simulation.
The authors would like to thank Tijana Zrnic, Anastasios Angelopoulos, and Allen Z. Ren for insightful discussions. The authors were partially supported by the NSF CAREER Award \(\#2044149\), the Office of Naval Research (N00014-23-1-2148), and the Sloan Fellowship. A. Badithela is supported by the Presidential Postdoctoral Fellowship at Princeton University.